




 無論是追球玩的小朋友、突然出現的牛群還是拋錨的汽車,這些意外障礙對于汽車駕駛者來說都是致命的。但是來自斯坦福大學的研究人員經過努力,已經研發出了相關的激光技術,可以預見到這樣的危險。
無論是追球玩的小朋友、突然出現的牛群還是拋錨的汽車,這些意外障礙對于汽車駕駛者來說都是致命的。但是來自斯坦福大學的研究人員經過努力,已經研發出了相關的激光技術,可以預見到這樣的危險。
近日,斯坦福大學 SCIL(雷鋒網新智駕注:Stanford Computational Imaging Lab)實驗室的研究人員在 Nature 雜志上發表了論文,對外闡述了這一新型激光技術到底是如何工作的。
基于這一技術的激光系統能夠有效的產生藏在轉角后物體的圖像,讓自動駕駛汽車可以提前“看見”還未出現在視域中的障礙物。

“有一種先入為主的觀念是,你沒法對那些沒有被攝像機直接看見的物體進行成像處理,而我們找到了跨越這些限制的辦法。”論文聯合作者、斯坦福大學博士后 Matthew O'Toole 如是表示。
他們找到的解決之道是基于激光雷達技術的方案。大家知道激光雷達很多時候用于測繪,其技術原理主要是通過向物體表面發射激光脈沖,并且測量光反射回來所需要的時間,這些數據之后會被研究人員用作搭建物體表面的 3D 模型。
不過斯坦福大學的新技術在這個基礎上更進一步,使用激光來探測轉角之后的物體,“幾乎就是一種魔法,”O'Toole 感嘆。
為了更直觀地解釋這一技術的原理,斯坦福大學還為這個團隊和他們的技術拍攝了一段闡述短片。
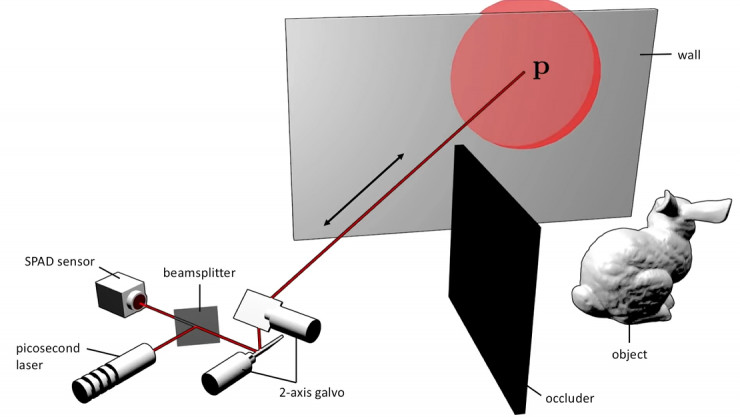
在短片中,O'Toole 和他的同事們描述了他們是如何搭建起一個演示模型的。這個模型中,激光發射器和光子探測器被放置在被探測物體(實際是一只兔子)旁邊墻壁(P 字母所在的位置)的前面,同時在被探測物體與激光發射器、光子探測器之間,是一塊實體擋板,制造了一種轉角的情境。
在這個場景中,激光脈沖(深紅的直線)開始以某個角度向墻壁發射,脈沖打在墻壁上后,產生反射,這里的反射是向多個角度發散的。
整個過程中,研究團隊對于收集直接從墻壁反彈到探測器上的光子并不感興趣,他們想收集的是經過墻壁反彈后,繼續射向那只兔子然后再反彈、分散后的光子。“我們尋找的是經過第二次、第三次,甚至是第四次反彈之后的光子,這樣的光子能夠對隱藏物體進行編碼和模型構建。”O'Toole 解釋稱。
上述的流程存在的一個問題是,射出的激光脈沖打在了墻上的某個點,而團隊要收集的返回信號則是來自于另一個點。這里,O'Toole 和他的同事使用了一種獨特的技術,可以讓激光發射器和光子探測器指向相同的一點。
然后,團隊利用信號時差的原理將那些直接反彈回來的光子移除掉,算法將那些保留下來的光子重建。塑形,逐漸形成清晰的針對轉角隱藏物體的 3D 模型。

“這是一個非常簡單的調整成像的方法,但它對你如何從這些信息中重建圖像具有重要意義。”O'Toole 表示。他還指出,這樣的設置占用更少的內存,處理起來也沒那么費力,還能生成更高分辨率的圖像。
在完成了對上述演示中那只兔子的成像之后,O'Toole 所在的團隊又將他們的技術運用到了現實生活中,包括對轉角的“Exit”字樣進行 3D 重建。

而說到這樣一項新技術的拓展應用時,O'Toole 說因為道路標識和自行車等物體的高反射性特質,所以他們的激光技術很適合于運用到自動駕駛汽車領域。
不過,很多的障礙依然存在。
比如,對于墻體的初次掃描要花上一分鐘到幾個小時不等,這是影響系統處理速度穩定性的重要因素;而且,針對一些反射性不那么強的物體如人體、動物等等,系統如何應對;此外,面對室外強光環境時,這項技術如何應對?
無疑,斯坦福大學的團隊還需要思考更多。
轉載請注明出處。

 相關文章
相關文章
 熱門資訊
熱門資訊
 精彩導讀
精彩導讀






























 關注我們
關注我們

